
In the rapidly evolving world of artificial intelligence (AI), researchers are continuously looking for innovative ways to improve the efficiency and cost-effectiveness of AI models. One of the most significant challenges in AI is managing the high costs of inference — the expense associated with running a pre-trained model on large-scale data.
DeepSeek, a leading AI research company, has recently introduced an experimental breakthrough in this area: a model that dramatically reduces API costs, particularly in long-context operations. This innovation, known as DeepSeek Sparse Attention, promises to reduce the computational costs of using transformer models by up to 50% in long-context scenarios.
But how exactly does it work? And what does this mean for businesses, developers, and the broader AI ecosystem? Let’s dive into this revolutionary approach and explore how it is set to change the game for AI inference costs.
What Is Sparse Attention, and Why Does It Matter?

At the core of DeepSeek’s innovation is a technique known as Sparse Attention, which addresses a major pain point in transformer-based models. Transformers, which are the foundation of many state-of-the-art models in AI (including GPT and BERT), rely on attention mechanisms to process input sequences. However, the attention mechanism in traditional transformers can be computationally expensive, especially when working with long-context sequences. As the length of the input increases, the cost of inference grows exponentially.
The Problem with Long-Context Sequences in AI Models
In traditional transformer models, the attention mechanism processes the entire input sequence at once, leading to high computational demands. As the sequence length increases, the complexity grows quadratically, making it highly inefficient for long texts, such as lengthy documents or long-term memory in conversational models.
The deeper the context that needs to be considered, the more computational resources are required, leading to sky-high API usage costs. This has been one of the main barriers for businesses and developers wanting to implement AI solutions at scale, especially when working with long-form content like legal documents, books, or multi-turn conversations.

Enter DeepSeek Sparse Attention
DeepSeek’s V3.2-exp model introduces a solution to this problem with its Sparse Attention system. Rather than processing the entire input at once, this system focuses only on the most relevant portions of the input, dramatically reducing the computational load.
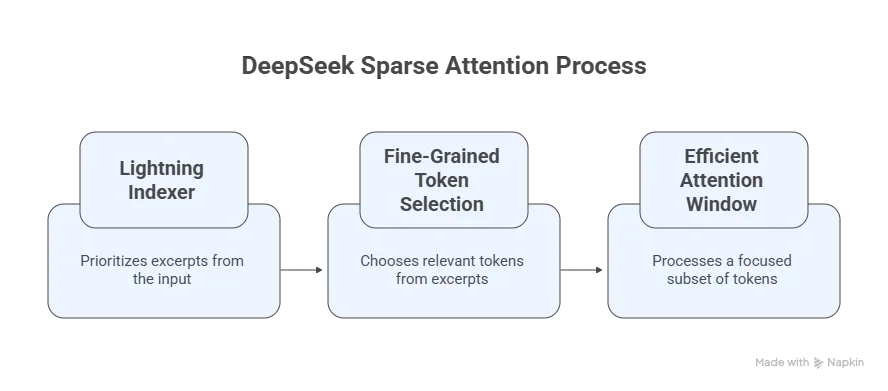
Let’s break down how it works:
-
Lightning Indexer: The first step involves a module known as the lightning indexer, which intelligently prioritizes specific excerpts from the full context window. This module uses advanced algorithms to identify the most important parts of the input, significantly narrowing down what needs to be processed.
-
Fine-Grained Token Selection System: After prioritizing the excerpts, the model uses a fine-grained token selection system to choose the most relevant tokens from the prioritized excerpts. This system ensures that only the most pertinent information is considered, drastically reducing the number of tokens that need to be loaded into the model’s attention window.
-
Efficient Attention Window: By processing a smaller, more focused subset of tokens, the Sparse Attention model can handle long-context operations with a fraction of the computational cost. This allows the system to run over extended contexts without incurring the typical high expenses of traditional models.
The Benefits: How Does Sparse Attention Cut API Costs?
One of the key benefits of DeepSeek’s Sparse Attention model is its ability to cut API costs by up to 50% for long-context operations. Preliminary tests have shown that when using this model, the costs of a simple API call can be halved compared to conventional transformer-based models.
This reduction in API costs is particularly valuable for businesses and developers working with large datasets or long sequences, such as:
-
Long-form content generation: AI-driven content creation tools that need to process long articles, blogs, or reports.
-
Legal and medical documents: Analyzing lengthy documents or contracts where context over multiple pages is essential.
-
Multi-turn conversations: In chatbot applications or virtual assistants where maintaining context across multiple interactions is key.
The ability to scale AI applications cost-effectively opens up new possibilities for businesses that rely on long-context data but have been held back by the financial burden of high inference costs.
What Sets DeepSeek Apart?
DeepSeek’s approach stands out in a few key ways:
-
Cost Efficiency: Unlike other models that simply scale with the context length, DeepSeek’s Sparse Attention system reduces the computational overhead by processing only the relevant parts of the input. This results in substantial savings in infrastructure costs, especially for businesses running multiple models or using AI services extensively.
-
Open-Weight and Accessible: The model is open-weight and available on Hugging Face, a popular platform for machine learning models. This makes it easy for developers and researchers to access and test the model, fostering collaboration and independent validation of its claims.
-
Improvement over Traditional Transformers: By refining the attention mechanism and reducing the number of tokens processed, Sparse Attention significantly improves the efficiency of transformer models without sacrificing performance. This makes it a viable option for both real-time and batch-processing tasks.
-
Scalability: The reduction in API costs is not just for a few isolated use cases but is scalable across multiple industries. Whether it’s AI-powered chatbots or long-form content generation, the benefits are wide-reaching.

What Does This Mean for the AI Ecosystem?
The introduction of DeepSeek’s Sparse Attention model could have significant implications for the broader AI ecosystem. As AI models continue to grow in size and complexity, the cost of running these models has become one of the major barriers to adoption. By focusing on cost optimization, DeepSeek has created a pathway for businesses to implement AI at a larger scale, without the prohibitive costs that have previously limited its use.
It’s also worth noting that competition in the AI field is heating up. DeepSeek’s innovation is likely to inspire other companies, both in the U.S. and globally, to explore similar solutions. As AI inference costs become a focal point of research, we may see more breakthroughs aimed at making AI models more affordable, efficient, and accessible.
FAQs on DeepSeek’s Sparse Attention Model
-
What is Sparse Attention in AI?
Sparse Attention is a technique that reduces the computational cost of processing long-context sequences by focusing on the most relevant parts of the input rather than processing the entire sequence. -
How does Sparse Attention cut API costs?
By prioritizing the most important excerpts from the input context and processing fewer tokens, Sparse Attention drastically reduces the number of computations required, lowering the cost of each API call by up to 50%. -
Is DeepSeek’s Sparse Attention model available for public use?
Yes, the model is open-weight and available on Hugging Face, allowing developers and researchers to access and experiment with it freely. -
What types of applications can benefit from Sparse Attention?
Applications that require long-context processing, such as long-form content generation, legal document analysis, and multi-turn chatbots, can all benefit from Sparse Attention. -
How can businesses take advantage of Sparse Attention for their AI projects?
By integrating Sparse Attention into their AI systems, businesses can reduce the costs associated with running large models and scale their operations more efficiently without sacrificing performance.
Resource Center
These aren’t just blogs – they’re bite-sized strategies for navigating a fast-moving business world. So pour yourself a cup, settle in, and discover insights that could shape your next big move.
What Are the Latest Trends in Digital Transformation for 2026?
Digital transformation is no longer a strategic option—it has become a foundational necessity for organizations aiming to remain competitive in a rapidly evolving digital economy. As we move into [...]
What Technologies Are Used in Digital Transformation Services?
Digital transformation is no longer a future ambition—it is a present-day business necessity. Organizations across industries are rapidly evolving their operations, customer experiences, and business models by integrating advanced [...]
What Role Does Data Analytics Play in Digital Transformation?
In today’s rapidly evolving digital landscape, organizations are no longer relying on intuition or traditional methods to drive business decisions. Instead, data analytics in digital transformation has emerged as [...]
