
In the last few years, generative AI has moved from an experimental technology to a critical business enabler. But while base models like GPT, Gemini, Llama, Claude, and others are powerful, they are still generalists. As I work with organisations to integrate generative AI into their platforms, one insight becomes consistently clear: real competitive advantage comes only when you fine-tune or customise the model for your own domain, product, workflow, or internal knowledge.
Many businesses struggle with where to start, what approach to use, how much data is required, and what level of customisation actually makes sense in terms of ROI. So, this blog answers a single question in depth:

How do you fine-tune or customise a generative AI model for your domain or product?
To answer this precisely, I will break down the practical steps, technical considerations, tools, common pitfalls, and real-world lessons we have learned while implementing fine-tuned AI solutions for multiple companies.
1. Understanding What “Customising a Generative AI Model” Really Means
Before we jump into the how, it’s important to understand what we are customising. When we talk about tailoring a generative AI model, we generally refer to four possible approaches:
1. Prompt Engineering
Using smart instructions to guide the model without changing its parameters.
✔ Quick
✔ No training cost
✔ Best for simple domain tasks
2. Retrieval Augmented Generation (RAG)
Attaching external data (documents, knowledge base, product FAQs, code, etc.) to the model at runtime.
✔ Keeps data updated
✔ Lower cost than full fine-tuning
✔ Works best for domain knowledge queries
3. Parameter Efficient Fine-Tuning (PEFT)
Training additional “adapter layers” (LoRA, QLoRA etc.) without modifying the full model.
✔ Cost-efficient
✔ Good accuracy gains
✔ Works well for product-specific tasks
4. Full Fine-Tuning
Modifying all parameters of the base model using high-quality training data.
✔ Maximum accuracy
✔ Needed for highly specialised tasks
✘ Expensive and rarely needed
Stats: According to industry benchmarks, PEFT-based tuning can reduce GPU costs by up to 60–80% compared to full fine-tuning while achieving 90–95% of the performance gain.

2. Identifying the Real Use-Case for Customisation
From my experience, companies often jump into fine-tuning before defining what they actually want the model to do. In reality, the process starts with a clear problem statement.
Ask questions like:
-
What exact task do we want AI to perform?
(classification, summarization, generation, code review, decision support, etc.) -
Where is the model currently failing?
(hallucinations, lack of domain understanding, accuracy issues) -
What domain-specific behaviours are required?
(legal compliance, medical terminology, product catalog knowledge) -
Will customising the model significantly reduce manual effort or errors?
When these questions are answered, we identify whether the business needs:
-
Prompt optimisation
-
RAG (for knowledge-heavy cases)
-
PEFT/fine-tuning (for behaviour-specific training)
3. Preparing and Structuring Domain Data for Training
Data is the single most critical element in AI customisation. The model performance depends heavily on:
-
Quality of data
-
Consistency
-
Domain-specific coverage
-
Instruction format
-
Noise removal
Based on projects we’ve worked on, the most effective dataset formats include:
a) Instruction–Response Pairs
b) Conversation Logs
Used for AI agents, chatbots, support systems.
c) Task Demonstrations
d) Domain Knowledge Documents
Policies, manuals, product guides converted into training chunks.
e) Synthetic Data
Sometimes generated using a larger model under expert supervision.
Practical Insight:
For most enterprise fine-tuning, 2,000–20,000 well-curated examples are enough to get high-quality results.
In comparison, general LLMs are trained on trillions of tokens — you don’t need that scale.
4. Choosing the Right Model for Customisation
Model selection depends on:
-
Use-case type
-
Regulatory requirements
-
Data privacy constraints
-
Deployment preference (cloud vs on-premise)
Common choices:
Open-source Models
Llama 3, Mistral, Falcon, Gemma
✔ Full control
✔ Can be tuned locally
✔ Best for privacy-sensitive sectors
Closed-source Models
OpenAI GPT-4.1, Gemini 1.5, Claude 3.5
✔ Higher reasoning abilities
✔ Zero maintenance
✔ Fine-tuning (for some models) can be expensive
Small/Custom Models
Phi, LLaMA 3.1 8B, Mistral 7B
✔ Lightweight
✔ Perfect for mobile/on-device use
In 2025, most companies prefer 8B–70B parameter open-source models for fine-tuning to maintain ownership of data behaviour.

5. Implementing the Fine-Tuning or Customisation Workflow
Below is the practical, step-by-step process we follow in real projects:
Step 1: Define Custom Behaviour
Examples:
-
“The model should talk like our brand.”
-
“The model should use internal product terminology.”
-
“The model should never hallucinate financial data.”
-
“The model should recommend X based only on approved knowledge.”
Step 2: Build or Collect the Dataset
This includes:
-
Formatting data into training pairs
-
Validating examples manually
-
Removing noise & duplicates
-
Balancing examples across categories
-
Annotating special instructions
Step 3: Choose the Customisation Method
For accurate domain answers → RAG
For changing model behaviour → PEFT
For completely new tasks → Full Fine-tuning
Step 4: Train with Evaluation Loops
We use:
-
QLoRA / LoRA for efficient training
-
Early stopping to avoid overfitting
-
Mixed precision training (FP16, BF16)
-
3-level evaluation (human, automated, domain-expert)
Benchmark:
In a typical enterprise setting, fine-tuning an 8B model with LoRA takes 3–6 hours on a modern GPU machine.
Step 5: Integrate the Model with Deployment Architecture
Depending on requirements:
-
API deployment (FastAPI, Node.js, .NET)
-
On-device inference for field apps
-
Multi-agent orchestration
-
Cloud platforms (AWS Sagemaker, Azure, GCP)
-
Vector DB integration (for RAG models)
We ensure:
-
High throughput
-
Low latency
-
Scalable inference
-
Monitoring for drift and behaviour changes
Step 6: Continuous Evaluation & Improvement
Post-deployment, we monitor:
-
Accuracy degradation
-
User feedback loops
-
Mistake logging
-
Domain-specific hallucinations
-
Content safety issues
We then schedule periodic improvement cycles (usually every 3–6 months).
6. Practical Challenges and How We Solve Them
Over time, we’ve encountered several real-world constraints:
Challenge 1: Not Enough Training Data
Solution:
Generate synthetic training data under expert supervision.
Challenge 2: Hallucinations in Domain Cases
Solution:
Use RAG with strict citation enforcement.
Challenge 3: High Fine-Tuning Cost
Solution:
Use PEFT/QLoRA and smaller models that can outperform larger untuned models.
Challenge 4: Keeping Data Updated
Solution:
Continuous RAG indexing + periodic mini-tuning.
Challenge 5: Model Overfitting on Narrow Data
Solution:
Mix general training examples with domain examples (30:70 ratio works well).
7. When Should You Fine-Tune vs Use RAG?
| Scenario | RAG | Fine-Tuning |
|---|---|---|
| Large knowledge documents | ✔ | ✘ |
| Product manuals & FAQs | ✔ | ✘ |
| Domain-specific writing style | ✘ | ✔ |
| Changing behaviour | ✘ | ✔ |
| Classification tasks | ✘ | ✔ (training required) |
| Reasoning improvement | ✘ | ✔ |
| Legal/medical/finance accuracy | ✔+Fine-Tune | ✔ |
Most companies begin with RAG and add fine-tuning only when behaviour needs to change deeply.
8. Expected Business Impact (Based on Real Implementation Stats)
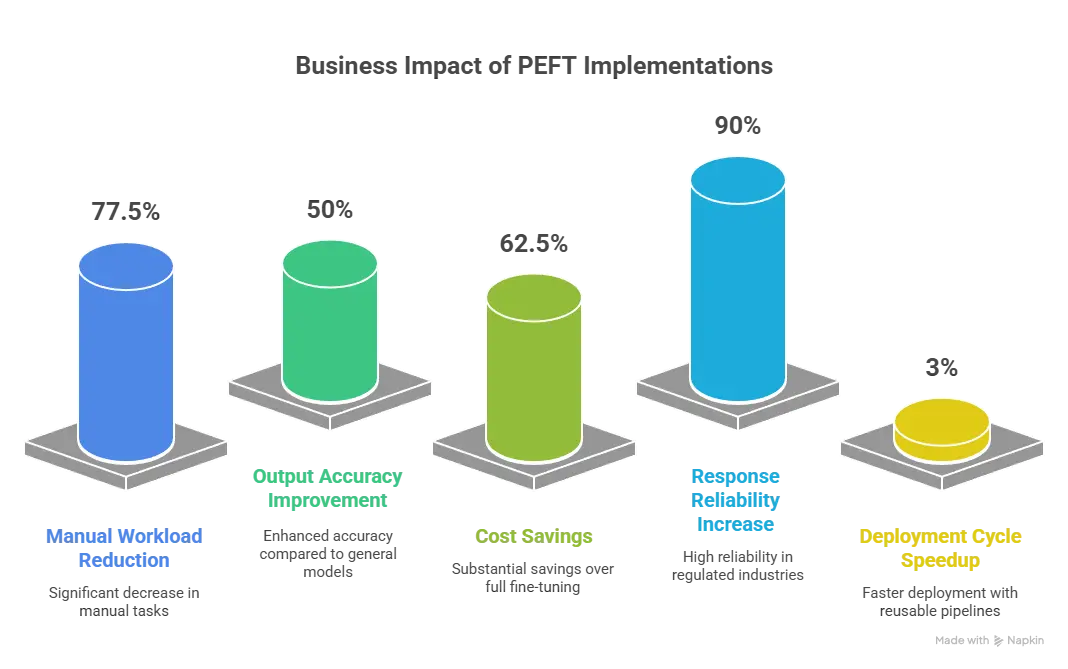
From the implementations we have done across healthcare, SaaS, finance, HR tech, and ecommerce:
-
70–85% reduction in manual workload for domain-specific tasks
-
40–60% improvement in output accuracy vs general models
-
50–75% cost savings using PEFT instead of full fine-tuning
-
Up to 90% increase in response reliability in regulated domains
-
2–4x faster deployment cycles with reusable training pipelines
These numbers clearly show that domain-specific fine-tuning is not just a technical improvement—it is a business growth accelerator.
FAQs
1. What is the best way to customise a generative AI model for a specific domain?
The best approach depends on the use case—RAG is best for domain knowledge, while PEFT or fine-tuning is better when changing the model’s behaviour or tone.
2. How much training data is needed for fine-tuning?
A typical enterprise fine-tuning task needs 2,000–20,000 high-quality examples, depending on complexity.
3. What is the difference between RAG and fine-tuning?
RAG adds external knowledge at inference time, while fine-tuning permanently changes how the model behaves based on training data.
4. How expensive is it to fine-tune a generative AI model?
Using methods like LoRA/QLoRA, costs can drop by 60–80%, and most 7B–13B models can be tuned on a single GPU system.
5. Why does my fine-tuned model still hallucinate sometimes?
Hallucinations typically occur due to data imbalance, insufficient domain examples, or absence of a RAG system. Adding knowledge retrieval or improving dataset quality usually resolves this.
Resource Center
These aren’t just blogs – they’re bite-sized strategies for navigating a fast-moving business world. So pour yourself a cup, settle in, and discover insights that could shape your next big move.
How Is Generative AI Changing Software Development?
The evolution of software development has always been shaped by innovation—from the rise of agile methodologies to the adoption of cloud-native architectures. Today, a new paradigm is rapidly redefining [...]
How Are Businesses Using Generative AI to Improve Productivity?
In today’s rapidly evolving digital economy, productivity is no longer driven solely by human effort or traditional automation. Businesses are increasingly leveraging generative AI for business productivity to unlock [...]
How Can Generative AI Improve Data Analysis and Insights?
In today’s data-driven economy, organizations are inundated with vast volumes of structured and unstructured data. While traditional analytics tools have played a critical role in extracting insights, they often [...]
