
In today’s rapidly evolving tech landscape, building intelligent, responsive, and scalable applications is paramount. At Inceptive Marketing, we’ve harnessed the combined power of Qdrant, an efficient vector database, and Gemini 2.5, a state-of-the-art foundation model, to craft smarter, more intuitive experiences. In this blog post, we’ll share how we integrate Qdrant with Gemini 2.5, describe our implementation approach, and explain how this synergy delivers advanced search, recommendation, and personalization capabilities.
Introduction
As an innovation-driven team with over 20 years of marketing and technology experience, we understand the importance of using infrastructure that supports both rapid development and powerful AI capabilities. Qdrant enables vector similarity search, while Gemini 2.5 brings advanced natural language understanding and generation. Together, they form a high-performance stack for building next-generation applications—especially recommendation engines, semantic search, and contextual chatbots.
Why We Chose Qdrant and Gemini 2.5
-
Qdrant (vector similarity search engine): We needed a vector database optimized for semantic search, high throughput, and low latency. Qdrant supports efficient nearest-neighbor search, on-the-fly filtering, and hybrid queries. It provides scalability and performance, empowering us to handle large embeddings with ease.
-
Gemini 2.5 (AI model): As a cutting-edge model offering strong natural language understanding and reasoning, Gemini 2.5 performs exceptionally well on tasks such as embedding generation, semantic matching, summarization, and even multi-turn conversational AI. Integrating Gemini 2.5 allows us to generate high-quality embeddings and responses.
The combination of vector database (Qdrant) and large language model (Gemini 2.5) lets us build applications that understand user intent semantically.
Our Implementation Approach
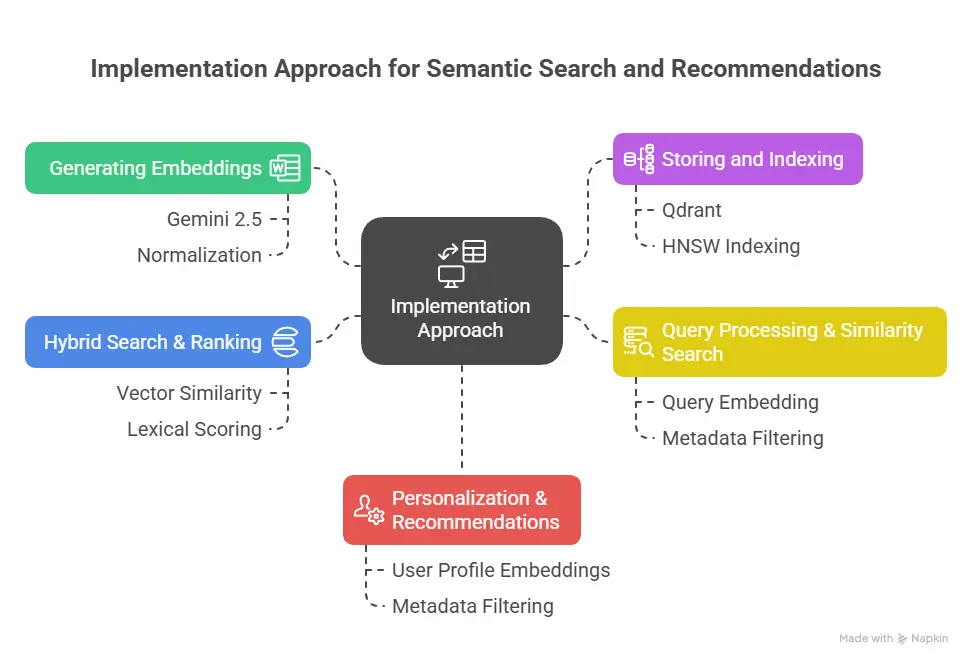
3.1 Generating Embeddings
We first use Gemini 2.5 to generate embedding vectors for content items—such as product descriptions, articles, FAQs, or user queries. These embeddings serve as dense, numerical representations capturing semantic meaning.
-
Step by step:
-
Feed textual inputs into Gemini 2.5.
-
Extract embeddings from its internal layers (e.g., the “embedding” endpoint or hidden activations).
-
Normalize embeddings to ensure consistency in vector space.
-
3.2 Storing and Indexing with Qdrant
Once we have embeddings, we push them into Qdrant:
-
Choose a collection per domain or content type (e.g., “products”, “articles”).
-
Define metadata fields (e.g., title, category, publication date).
-
Use HNSW indexing for fast approximate nearest-neighbor search.
-
Tune index parameters—such as
ef_constructionandm—for optimal recall and latency.
3.3 Query Processing & Similarity Search
When a user issues a query, we follow this pipeline:
-
Transform the query using Gemini 2.5 to produce a query embedding.
-
Run vector search in Qdrant to retrieve the top-k most semantically similar items.
-
Apply filters using metadata (e.g., date, category) to refine results.
-
Post-process results, such as reranking using domain-specific heuristics or combining with traditional search signals (keyword matching, CTR data, etc.).
3.4 Hybrid Search & Ranking
To ensure both semantic relevance and keyword precision, we implement hybrid search. We combine:
-
Vector similarity (from embeddings + Qdrant)
-
Lexical scoring (BM25 or TF-IDF through a traditional text index)
We merge the two ranks with weighted scoring, dynamically adjusting based on user intent (e.g., for conversational queries, give more weight to embedding similarity; for precision queries, emphasize lexical accuracy).
3.5 Personalization & Recommendations
By generating user profile embeddings—either from past interactions, browsing history, or preferences—we can issue similarity queries against content embeddings, enabling personalized recommendations. Qdrant’s metadata filtering ensures we avoid repeated content or restrict recommendations by recency or other business rules.
Benefits We’ve Achieved
4.1 Enhanced User Satisfaction
Semantic search powered by Qdrant and Gemini 2.5 provides users with more relevant results, even when their queries are vague or lack exact keywords. The synergy improves discovery and reduces bounce rates.
4.2 Low Latency at Scale
Using Qdrant’s efficient approximate nearest neighbor (ANN) indexing, we serve embedding searches in milliseconds—even across millions of vectors. This makes AI-powered features viable in production environments.
4.3 Flexible, Real-Time Updates
As new content arrives or user profiles evolve, we can incrementally embed and update Qdrant collections. This flexibility means fresh, personalized results in real time.
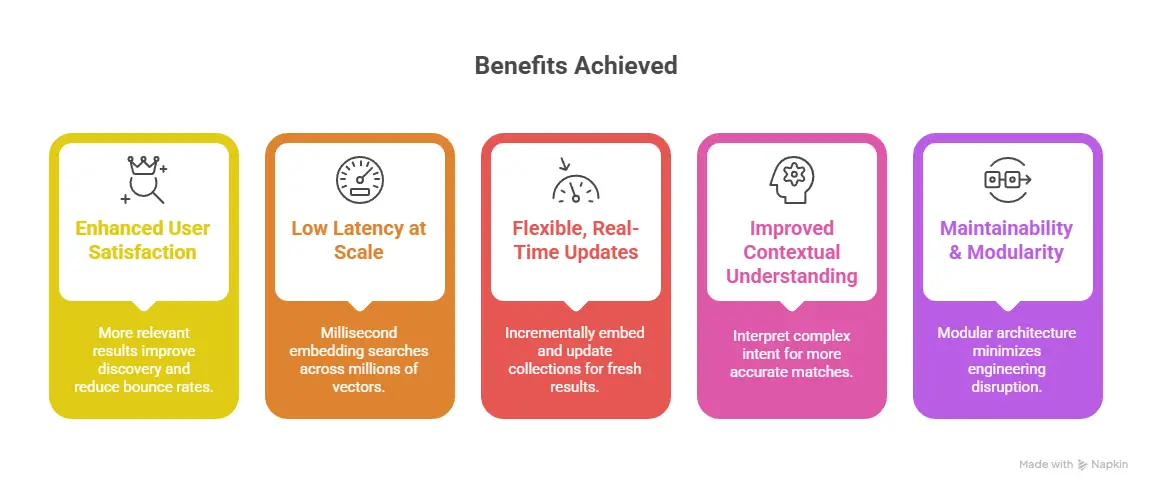
4.4 Improved Contextual Understanding
Gemini 2.5’s deep language understanding allows us to interpret complex or multi-modal intent—like understanding user questions, paraphrases, or incomplete phrasing. Pairing that with vector search yields more accurate matches.
4.5 Maintainability & Modularity
Our architecture—embedding via Gemini 2.5, vector storage in Qdrant—is modular. If we need to swap in a different LLM or vector store, the integration points remain clean, minimizing engineering disruption.
Use Cases We’ve Built
5.1 Semantic Product Search
Users search product catalogs with queries like “eco-friendly hiking shoes under water resistance.” Gemini 2.5 turns this into embeddings, Qdrant retrieves semantically close matches, and we overlay product filters like “price < $200” or “rating ≥ 4 stars.”
5.2 Context-Aware Chatbot
We’ve developed chatbots that remember prior user queries and context. The system embeds conversation history, retrieves relevant document passages from Qdrant, and uses Gemini 2.5 to compose coherent, informed responses.
5.3 Content Recommendation Engine
On editorial platforms, we create “related articles” sections using similarity matching. Even for content without matching keywords, Qdrant surfaces them based on theme and tone similarity.
Best Practices & Lessons Learned
-
Normalize embeddings—embedding vectors from LLMs can vary in magnitude. We apply normalization to improve search consistency.
-
Tune index parameters—we experimented with
efandmvalues to find the best trade-off between recall and throughput. -
Combine signals wisely—hybrid search shines, but weight tuning per query type matters.
-
Monitor drift in embedding space—model updates or content drift can shift embedding distributions, so we regularly re-evaluate similarity thresholds.
-
Control costs—embedding models and vector search incur compute costs, so we batch embedding operations and cache popular queries to reduce model load.
Frequently Asked Questions (FAQs)
Q. What is Qdrant, and how is it useful with LLMs?
A. Qdrant is an open-source vector database that enables efficient vector similarity search, metadata filtering, and hybrid queries. When paired with LLMs like Gemini 2.5, it lets you store embedding representations and retrieve semantically relevant content at scale.
Q. How do I generate embeddings with Gemini 2.5?
A. Use Gemini 2.5’s embedding capabilities: send text input to the model’s embedding endpoint or access internal activations, then extract and normalize the resulting dense vectors for use with Qdrant.
Q. Can I do hybrid searches combining keyword and semantic search?
A. Yes. A hybrid search integrates semantic (vector similarity) results from Qdrant with classic lexical scores (like BM25). You rank results by combining both scores, adjusting weights depending on search intent for best relevance.
Q. What are best practices for using Qdrant at scale?
A. Use efficient HNSW indexing and tune parameters (ef_construction, m, ef_search).
Normalize embeddings.
Employ incremental indexing for new content.
Monitor embedding drift and refresh models or thresholds as needed.
Q. How can I personalize recommendations using Qdrant and Gemini 2.5?
A. You build user embeddings based on their interaction history or preferences, then query Qdrant for items whose embeddings closely match the user’s. Metadata filters (e.g., “recent,” “new,” or “not yet seen”) enhance personalization.
Final Thoughts
By combining Qdrant’s high-performance vector search capabilities with Gemini 2.5’s advanced embedding generation and natural language understanding, we’ve constructed smarter applications that deliver meaningful search, recommendation, and conversational AI features. The architecture is modular, scalable, and efficient—perfectly aligned with our long-term innovation strategy.
We hope this breakdown offers valuable insight into how vector databases and LLMs can be paired for smarter, more responsive applications. If you’d like to explore a specific section further or discuss implementation details, we’d be delighted to dive deeper.
Resource Center
These aren’t just blogs – they’re bite-sized strategies for navigating a fast-moving business world. So pour yourself a cup, settle in, and discover insights that could shape your next big move.
What Are the Latest Trends in Digital Transformation for 2026?
Digital transformation is no longer a strategic option—it has become a foundational necessity for organizations aiming to remain competitive in a rapidly evolving digital economy. As we move into [...]
What Technologies Are Used in Digital Transformation Services?
Digital transformation is no longer a future ambition—it is a present-day business necessity. Organizations across industries are rapidly evolving their operations, customer experiences, and business models by integrating advanced [...]
What Role Does Data Analytics Play in Digital Transformation?
In today’s rapidly evolving digital landscape, organizations are no longer relying on intuition or traditional methods to drive business decisions. Instead, data analytics in digital transformation has emerged as [...]
