

Cloud infrastructure makes life easy for IT people. The common task for any IT project is maintaining back-end data.
AWS provides database as service which is commonly known as Relation Database Service (RDS). It has the support of all popular databases like SQL server, MySQL, and PostgresSQL.
AWS RDS provides a built-in service for backup, which is configurable. It takes the snapshot of your entire DB instance and keeps it in AWS infra as a backup. Although this service work fabulously, there are times when you need to have database file natively stored on your machine.
This article will elaborate on the process of creating a .bak file from the AWS RDS SQL server instance.
Login to your AWS console and navigate to RDS, from the side menu locate the link for the options group as shown below
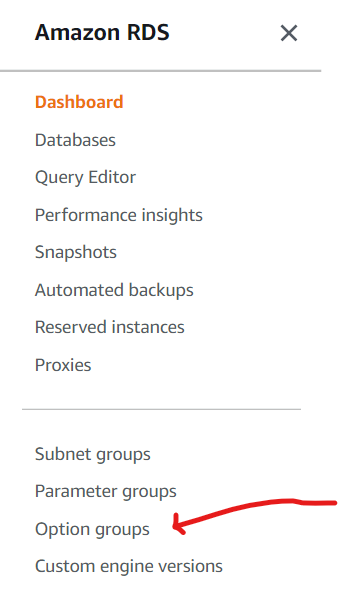
You will be redirected to the page for creating a new option group
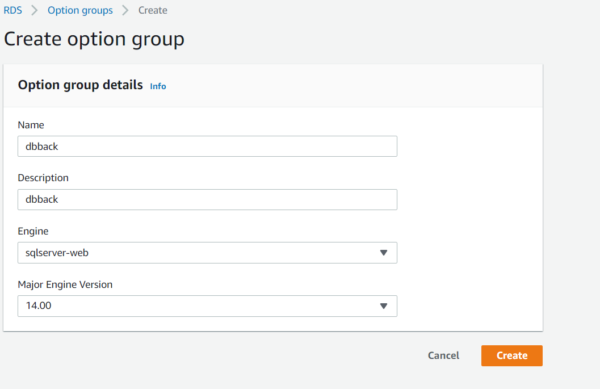
Provide appropriate name and description for option group, its essential to keep and Engine and its number the same as of RDS database.
Once you have created an option-group, you need to add an option you will be redirected to the screen for adding an option
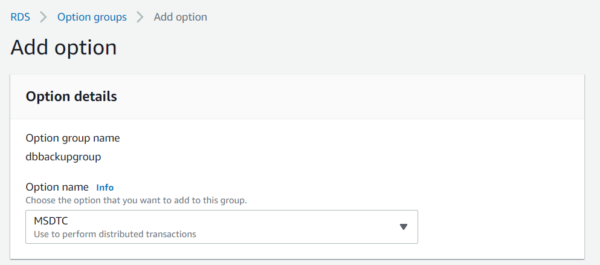
Select Sql server backup restore from the option dropdown

Create a new I am role, AWS will automatically grant access to this role for SQL server backup and restore
you can apply this option group to reflect immediately or at scheduled maintenance time.
For storing the backup file you need to create a bucket in S3 storage. Navigate to S3 storage and add the bucket as shown below
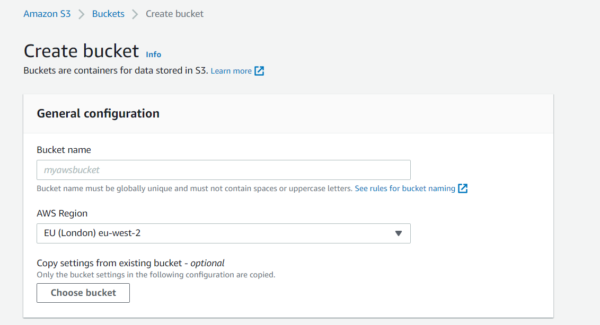
Keep the default settings as it is. Once you are ready with the bucket, All you need to do is to execute the below command on your MMC
exec msdb.dbo.rds_backup_database
@source_db_name=’database_name’,
@s3_arn_to_backup_to=’arn:aws:s3:::bucket_name/file_name.extension’
Replace database_name with the actual database name, and bucket_name with the actual name of the bucket.
Similarly, replace file_name.extension with the name of the file and its extension
It will create a backup file in s3 bucket.
Resource Center
These aren’t just blogs – they’re bite-sized strategies for navigating a fast-moving business world. So pour yourself a cup, settle in, and discover insights that could shape your next big move.
What Are the Latest Trends in Digital Transformation for 2026?
Digital transformation is no longer a strategic option—it has become a foundational necessity for organizations aiming to remain competitive in a rapidly evolving digital economy. As we move into [...]
What Technologies Are Used in Digital Transformation Services?
Digital transformation is no longer a future ambition—it is a present-day business necessity. Organizations across industries are rapidly evolving their operations, customer experiences, and business models by integrating advanced [...]
What Role Does Data Analytics Play in Digital Transformation?
In today’s rapidly evolving digital landscape, organizations are no longer relying on intuition or traditional methods to drive business decisions. Instead, data analytics in digital transformation has emerged as [...]
