

I hope you got an excellent idea of the number of things involved in creating an app that utilizes the potential of OpenAI.
Let’s get straight into action,
- Create a virtualenv:
Creating a virtualenv is an important starting point for creating the project, if you are a Windows user type in the following command to start the project
python -m venv myenv
myenv is the name of your virtual environment, this will create a directory structure for you.
2. Installing dependencies:
Below mandatory dependencies are required, create the file requirements.txt and execute the below command
pip install -r requirements.txt
In case of any issues please check the issue and install relevant dependencies, you need require to install additional dependencies such as supabase.
3. Directory structure
The directory structure is flexible, you can create one as per your requirement.
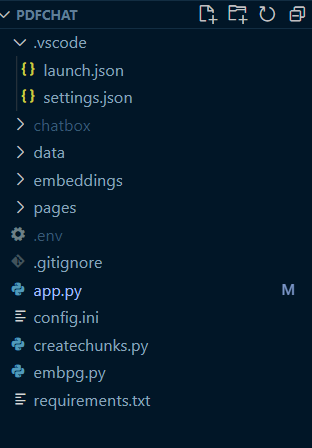
Chatbox: is a virtual environment.
Data: the main folder where you can keep your pdf files.
Pages: other pages of your application.
Embeddings: embeddings of your pdf files in case you decided to use FAISS-cpu for similarity search.
App.py: The entry point of the streamlit application.
Createchunks.py: this file contains the script for pdf reading and creating overlapping chunks along with FAISS embedding and storing them on the file system.
Embpg.py: Stores the embedding in Supabase PGVector
Config.ini: Stores the configuration parameters.
For the sake of completeness, we will follow the approach of storing embeddings in supabase PGVector.
PGVector is a new data type added in PostgreSQL for storing and performing vector-related operations.
Supabase is a no/low code platform built on top of PostgreSQL, you can create and store your data without needing to install PostgreSQL on your machine.
For more information, you can visit the supabase.com
Creating chunks:
As mentioned above in the directory structure, we have the data folder to place the pdf file.
The below code will loop through each file in the specified directory to get the pdf file.
Pdfreader is used to load and read the pdf content. The RecursiveCharacterTextSplitter is used to create the chunk size of the required size along with the overlap

TODOs:
- Check the chunks for a file name already exists or not, if not then create the chunks
Creating embeddings:
Before creating the embeddings, it is of utmost importance that we need to have the structure to store them. Creating embeddings via open API can incur costs hence once created we need to store them
As mentioned above we have used Supabase for this, we have created the table the structure of the table is as follows

The column classpage_embedding is defined as a vector, in addition to this column considering the application structure we have stored file_name also just to have the reference of content_chunk and file_name.
TODOs: Creating a separate table for storing master file information and then referencing it in the above table would be more appropriate.
Once the structure is ready we just need to follow the integration steps for utilizing the powerful supabase APIs for connections and connecting to the table for data manipulations.
The below function gets a pdf chunk as input, along with the file name. Assuming you have api_key for openai and openai dependency is installed the function below calls the embeddings API of openai and stores them in the supabase table.

Once you have done with the above you have almost done with the backend part of the application. You can set a watchdog or another kind of tool for automating the embeddings for the new files getting added to the folder.
Resource Center
These aren’t just blogs – they’re bite-sized strategies for navigating a fast-moving business world. So pour yourself a cup, settle in, and discover insights that could shape your next big move.
What Are the Latest Trends in Digital Transformation for 2026?
Digital transformation is no longer a strategic option—it has become a foundational necessity for organizations aiming to remain competitive in a rapidly evolving digital economy. As we move into [...]
What Technologies Are Used in Digital Transformation Services?
Digital transformation is no longer a future ambition—it is a present-day business necessity. Organizations across industries are rapidly evolving their operations, customer experiences, and business models by integrating advanced [...]
What Role Does Data Analytics Play in Digital Transformation?
In today’s rapidly evolving digital landscape, organizations are no longer relying on intuition or traditional methods to drive business decisions. Instead, data analytics in digital transformation has emerged as [...]
